


プロジェクト概要
これまで別技術でモノの管理を担ってきた大手企業のR&D部門様において、新たに画像AIを自社サービスへ取り込み、現場での「数量カウント」と「不良判定」を同一の仕組みで扱う取り組みが進められています。SCIENは、すでに社内でPoCを進めておられたモデル群を題材に、ファインチューニングの設計、アノテーション運用、タスク定義、そしてエッジ実装を見据えた軽量化方針までを横断的に助言するアドバイザリーとして参画しました。
カウントタスクのモデル選定とアノテーション設計
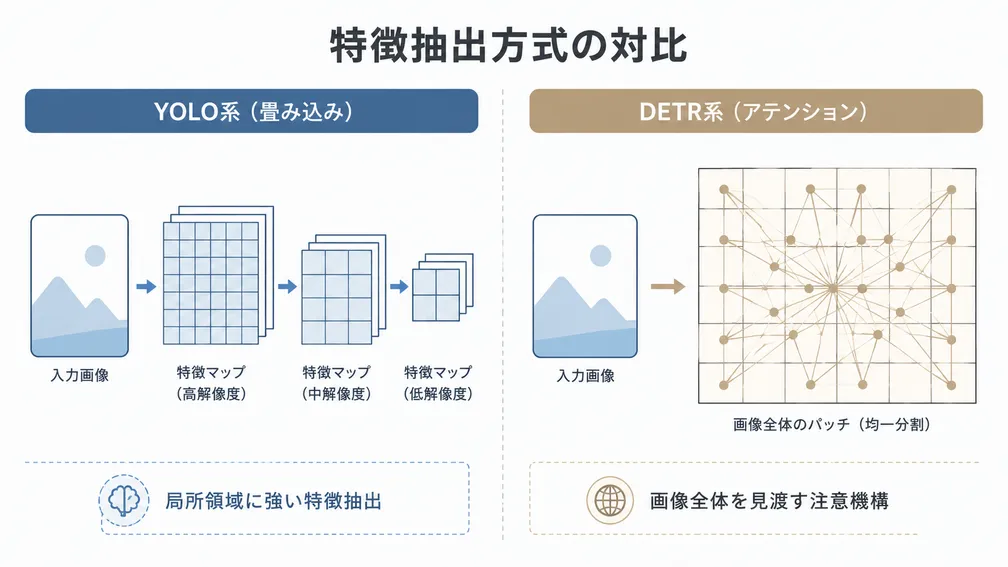
カウント対象は重なりや遮蔽が前提となる資材群で、単純な物体検出では取りこぼしが発生しやすい領域です。お客様側では既にYOLO系とDetection Transformer系(RT-DETR)の双方を試行されており、SCIENからは以下の観点で技術的な助言を行いました。
- バウンディングボックスが重なりやすい対象では、NMSに依存するYOLO系よりもアテンション機構で全体を見るDETR系の方が安定しやすいこと
- 全体ポリゴンと部分(底面など)のみのアノテーション戦略を比較し、検出対象を最も識別しやすい部位に絞る設計が現実的であること
- SAM等のオートラベリングはマニアックな対象では効きづらく、コピー&ペーストによる合成や対象特化のオーグメンテーション併用が現実解になり得ること
不良検出は「異常検知」と「形状推定」に分離する
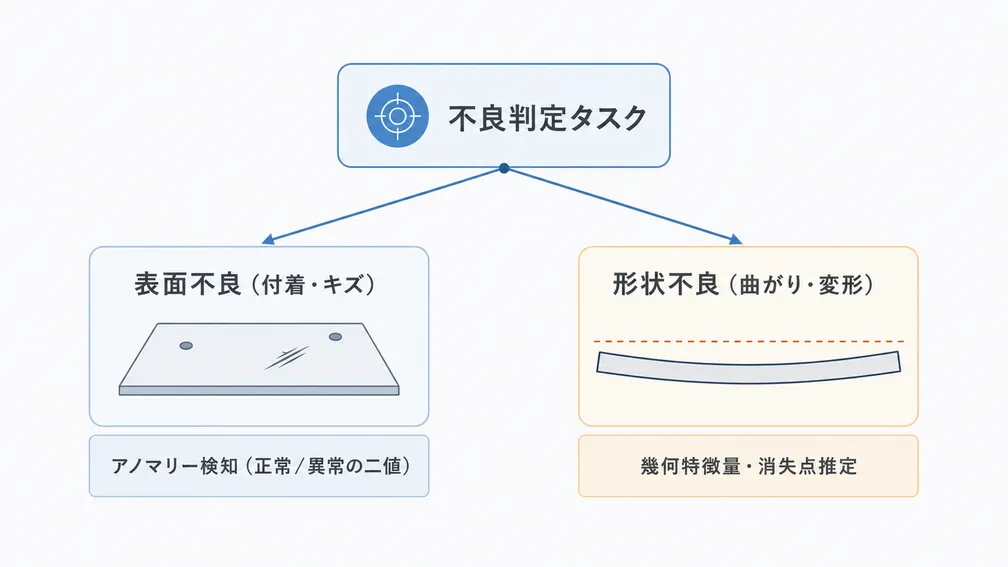
写真上で人にも判別が難しいレベルの曲がりや、付着・打痕といった不良を、すべて多クラスの物体検出で扱おうとすると、デコーダ側の分類が成立せず精度が頭打ちになります。SCIENは、不良タスクを次のように再構成することを提案しました。
- 付着・キズ系の表面不良:少数データでも成立しやすいアノマリー検知(正常/異常の二値)として扱う
- 曲がり・変形などの形状不良:消失点推定や補助線とのズレ判定など、幾何的な特徴量へ寄せる
- 熟練者の暗黙知が効く判定:CLIPベースの対照学習で、画像領域と説明テキストを一対一で結びつける学習データを設計する
異種の不良を同一ラベル空間に押し込まないことが、限られたデータで運用可能なモデルを成立させる前提になります。
学習済みモデルの扱いとファインチューニング指針
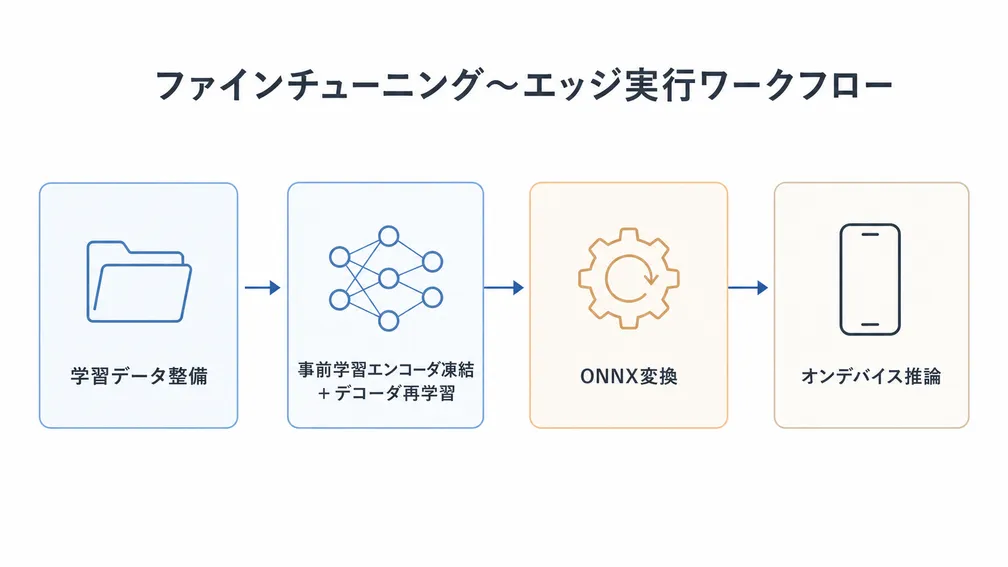
物体検出における「学習済みモデル」は、画像エンコーダのみ事前学習されたものと、全パラメータが特定データセットで学習されたものの二系統に分かれます。SCIENからは、Object365等で全パラメータをファインチューニングされたモデルをそのまま継続学習すると、元データセットのクラス(人物・車両など)が誤検出として残る挙動の背景を解説し、次のような方針を整理しました。
- 画像エンコーダ(Vision Transformer系・Swin Large系)の事前学習重みは凍結して再利用する
- デコーダおよび検出ヘッドは、自社データに合わせてランダム初期化から学習する
- 商用ノーコード学習プラットフォーム上で前段の事前学習を切り離せない場合は、Pythonベースでの自前学習パイプラインへの移行も選択肢に含める
あわせて、本格的にゼロから学習する場合のハードウェア構成(96GB級のGPUを前提としたバッチサイズ設計)まで含め、内製で進められる現実的なロードマップを提示しました。
エッジ実行を見据えた軽量化と運用設計
最終的な提供形態がスマートフォン上でのオンデバイス推論であることを踏まえ、SCIENからはONNXを経由した各種ランタイムへの変換と、変換時に詰まりやすい論点を共有しました。
- ONNXからTensorFlow Lite/CoreMLへの変換における演算子互換性の留意点
- 量子化を行う場合と行わない場合のトレードオフ、TensorRT等での最適化余地
- 学習環境はLinuxを基本とし、変換・デバッグ工程での再現性を担保する構成
クラウド側に推論を寄せず、現場端末で完結させる前提を崩さないまま、精度と推論速度の両立点を探る指針として整理しています。
本プロジェクトにおける価値
本アドバイザリーの価値は、単なるモデル比較に閉じず、タスク定義そのものを「カウント」「表面不良」「形状不良」へと分割し、それぞれに適したモデル設計・学習データ戦略・運用形態を提示した点にあります。お客様R&D部門様の内製開発力と、SCIENの最先端モデル実装知見を組み合わせることで、自社サービスへの画像AI組み込みを現実的なスケジュールで前進させる足場を整えました。
記事を共有


